【はじめに】
Mockitoとは、Javaのユニットテストをサポートするためのライブラリです。
テスト対象のクラスから呼び出されるクラス(オブジェクト)の代わりとなるオブジェクトを生成する機能を持ちます。
代わりとなるオブジェクトは、「モックオブジェクト」と呼ばれます。
図で説明すると以下の通りです。
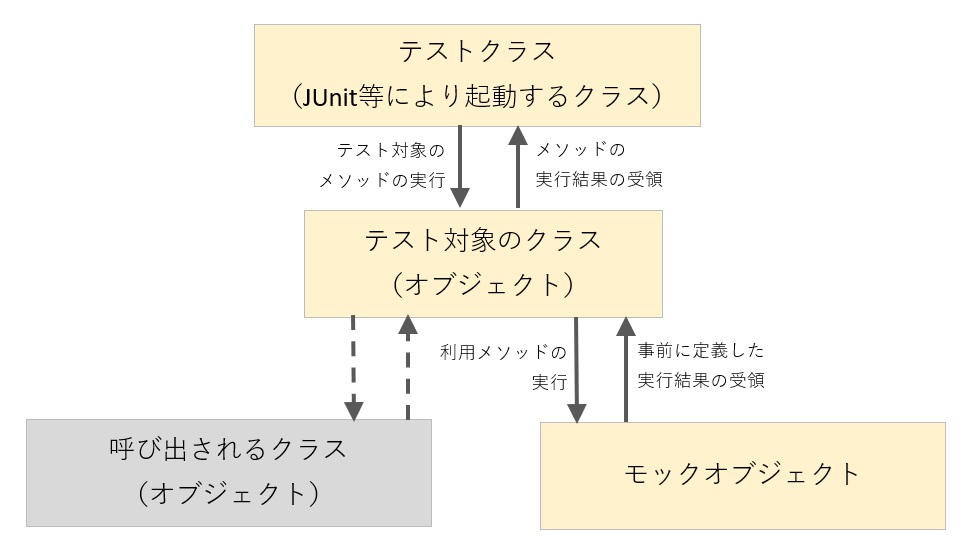
テスト対象のクラスから呼び出されるクラスをそのまま用いるとユニットテストが困難になる場合にMockitoが役立ちます。
例えば、そのクラスが開発中の場合に、開発完了前にユニットテストを行うことができるようになります。
また、そのクラスの出力が不定の場合(データベースや外部システムの状態に依存する、ランダム性がある、等)にも役立ちます。
実際に動かすと、Mockitoがどのようなライブラリなのか理解しやすいです。
この記事では、Eclipse上でのJavaプロジェクトの構築、JUnitを用いたテスト環境構築、Mockitoの導入、Mockitoを用いたテストの実施、という順を追って、Mockitoを実際に動かしてみます。
(Javaのバージョンは11です)
なお、JUnitを用いたテスト環境を構築する所までは、株式会社サイゼントが発行している「絶対にJavaプログラマーになりたい人へ(https://www.amazon.co.jp/%E7%B5%B6%E5%AF%BE%E3%81%ABJava%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9E%E3%83%BC%E3%81%AB%E3%81%AA%E3%82%8A%E3%81%9F%E3%81%84%E4%BA%BA%E3%81%B8%E3%80%82-%E3%82%B7%E3%82%B9%E3%83%86%E3%83%A0%E9%96%8B%E7%99%BA%E4%BC%9A%E7%A4%BE%E3%81%AE%E6%9C%AA%E7%B5%8C%E9%A8%93%E5%90%91%E3%81%91%E7%A4%BE%E5%86%85%E7%A0%94%E4%BF%AE%E3%82%92%E5%85%AC%E9%96%8B%E3%80%82%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0%E3%82%B9%E3%82%AF%E3%83%BC%E3%83%AB%E3%82%92%E9%81%8B%E5%96%B6%E4%B8%AD-%E6%A0%AA%E5%BC%8F%E4%BC%9A%E7%A4%BE%E3%82%B5%E3%82%A4%E3%82%BC%E3%83%B3%E3%83%88-ebook/dp/B0D2VJ3GF2)」の第一章~第三章に詳しく書かせていただいています。
環境構築に躓いてしまう方は、こちらも是非ご覧になってください!
【Eclipse上でのJavaプロジェクトの構築】
Eclipseを起動したら、画面上部のメニューバーから、「ファイル > 新規 > Java プロジェクト」を選択します。
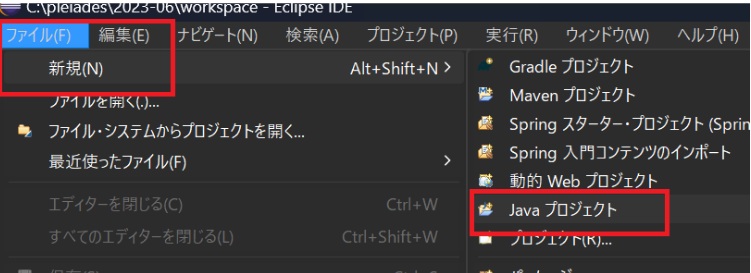
その後、プロジェクト名に任意のプロジェクト名を入力し、JREのバージョンにJava 11を選択したら、「完了」を押下します。
この手順で新規のJavaプロジェクトが作成されます。
その後、以下のクラスを作成します。
(クラスの作成は、新規で作成されたJavaプロジェクトを画面左部のプロジェクト・エクスプローラー上で「右クリック > 新規 > クラス」を選択することで作成できます)
・MyLogic.java
package mylogic;
public class MyLogic {
/* 商品コードから在庫量を取得 */
public int getStockAmount(String productCode) {
int stockAmount;
// 本当はDBアクセスを含む複雑な処理を行うが、今回はシンプルな処理とする
try {
stockAmount = Integer.parseInt(productCode);
} catch (Exception e) {
stockAmount = 0;
}
if (stockAmount < 0) {
stockAmount = 0;
}
return stockAmount;
}
}
・MyMain.java
package mymain;
import mylogic.MyLogic;
public class MyMain {
private static MyLogic myLogic = new MyLogic();
public static void main(String args) {
System.out.println("商品コードから在庫量を取得。");
String productCode = "0020";
System.out.println("商品コード:" + productCode);
System.out.println("在庫量:" + myLogic.getStockAmount(productCode));
}
}
その後、確認のため、プロジェクト・エクスプローラー上でMyMain.javaを「右クリック > 実行 > Java アプリケーション」で実行します。
以下のように出力されれば、ここまでの環境構築はOKです。
商品コードから在庫量を取得。
商品コード:0020
在庫量:20
【JUnitを用いたテスト環境構築】
次に、MyLogicクラスをテストするためのテストコードを作成します。
テストコードの内容は以下の通りです。
・MyJUnit.java
package mytest;
import static org.junit.jupiter.api.Assertions.*;
import org.junit.jupiter.api.Test;
import mylogic.MyLogic;
class MyJUnit {
private MyLogic myLogic;
@Test
void test() {
myLogic = new MyLogic();
String productCode = "0020";
assertEquals(20, myLogic.getStockAmount(productCode));
}
}
ここまでで、以下のようなフォルダ構成になっているはずです。
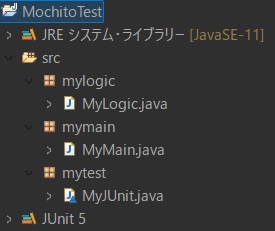
その後、確認のため、プロジェクト・エクスプローラー上でMyJUnit.javaを「右クリック > 実行 > JUnit テスト」で実行します。
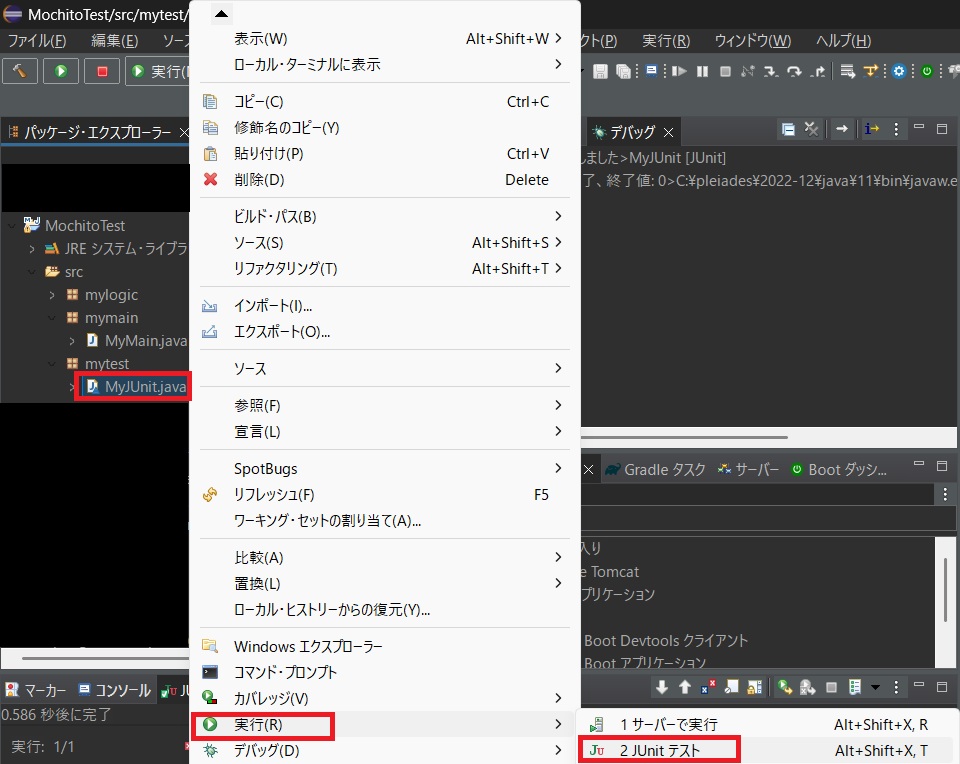
テストが成功すれば(緑色のバーが表示されれば)、ここまでの環境構築はOKです。
【より実践的なコードへの修正】
ここで、Mockitoの使用に適した実践的なソースコードに修正します。
ここでは、「MyLogic.java」を、商品コードに対応した在庫量を取得する「MyLogicSub.java」と、その結果を修正して返す「MyLogic.java」に分割します。
また、在庫量の取得ロジックに乱数を用いるようにします。
(実際はデータベース等の外部のリソースにアクセスすることで取得するのが一般的ですが、ここでは、「外部の状態に依存するために結果が不定になる」というのを表現するために乱数を用います)
MyLogicSub.javaを新たに作成します。
・MyLogicSub.java
package mylogic.sub;
import java.util.Random;
public class MyLogicSub {
/* 商品コードから在庫量を取得 */
public int searchStockAmount(String productCode) {
int stockAmount = 0;
// 本当はDBアクセスを行うが、今回はシンプルな処理とする
try {
stockAmount = Integer.parseInt(productCode);
// 取得結果が不定(外部に依存する)というのを乱数で表現
Random random = new Random();
stockAmount = stockAmount + random.nextInt(11) - 5;
} catch (Exception e) {
stockAmount = 0;
}
return stockAmount;
}
}
また、これまで作成してきたクラスも、クラス分割の方針に従って修正します。
・MyLogic.java
package mylogic;
import mylogic.sub.MyLogicSub;
public class MyLogic {
/* 商品コードから在庫量を取得 */
public int getStockAmount(String productCode, MyLogicSub myLogicSub) {
int stockAmount;
// DBアクセスにより在庫量を取得
stockAmount = myLogicSub.searchStockAmount(productCode);
// DBアクセスして得た結果を補正。今回は単純な処理とする。
if (stockAmount < 0) {
stockAmount = 0;
}
return stockAmount;
}
}
・MyMain.java
package mymain;
import mylogic.MyLogic;
import mylogic.sub.MyLogicSub;
public class MyMain {
private static MyLogic myLogic = new MyLogic();
public static void main(String args) {
System.out.println("商品コードから在庫量を取得。");
String productCode = "0020";
System.out.println("商品コード:" + productCode);
MyLogicSub myLogicSub = new MyLogicSub();
System.out.println("在庫量:" + myLogic.getStockAmount(productCode, myLogicSub));
}
}
・MyJUnit.java
package mytest;
import static org.junit.jupiter.api.Assertions.*;
import org.junit.jupiter.api.Test;
import mylogic.MyLogic;
import mylogic.sub.MyLogicSub;
class MyJUnit {
private MyLogic myLogic = new MyLogic();
@Test
void test() {
String productCode = "0020";
MyLogicSub myLogicSub = new MyLogicSub();
assertEquals(20, myLogic.getStockAmount(productCode, myLogicSub));
}
}
ここまでで、以下のようなフォルダ構成になっているはずです。

この状態でテストを実行すると、10回に9回以上の確率で失敗するように(赤色のバーが表示されるように)なります。
これは、在庫量の取得に乱数を用いるようにしたことで、期待結果の在庫量と一致しないケースが出てくるようになったためです。
このままではMyLogicクラスのユニットテストが難しくなるので、今後の手順でMockitoを用いることで問題を解決していきます。
【Mavenプロジェクトへの変換】
ライブラリを取り込む上では、ビルドツールを用いると便利です。
ここでは、ビルドツールにMavenを使用します。
まず、プロジェクト・エクスプローラー上で「プロジェクト名を右クリック > 構成 > Maven プロジェクトへ変換」を選択します。
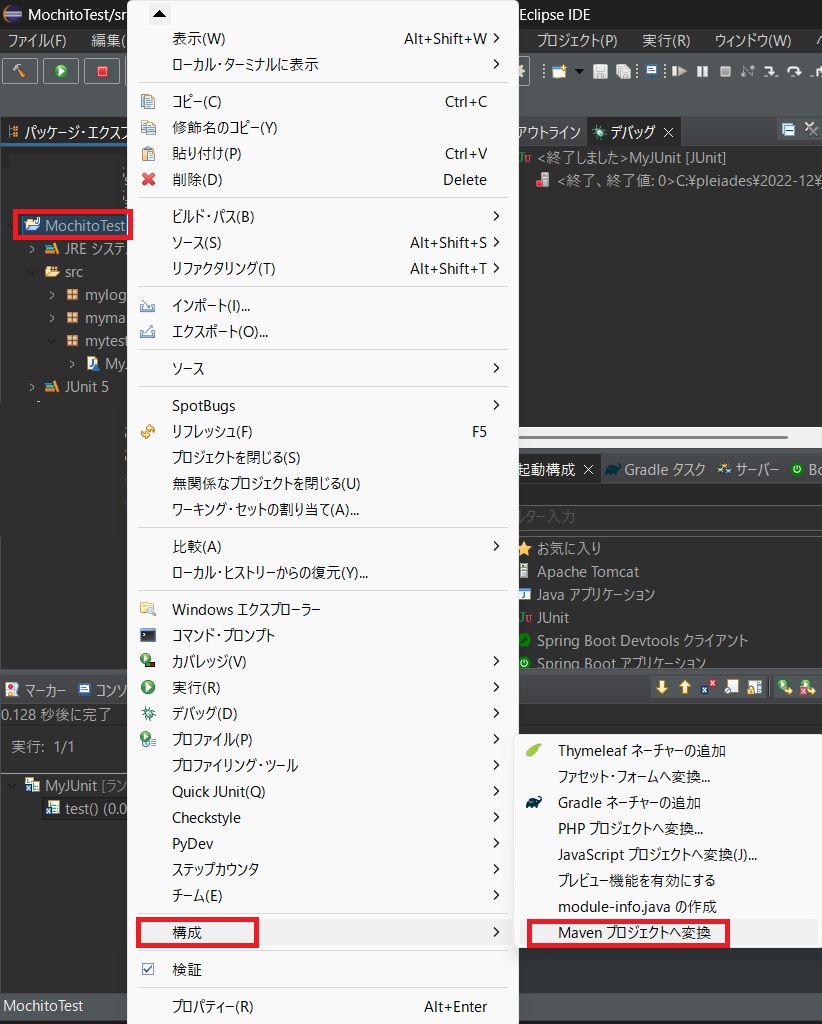
その後のポップアップでは完了を押下します。
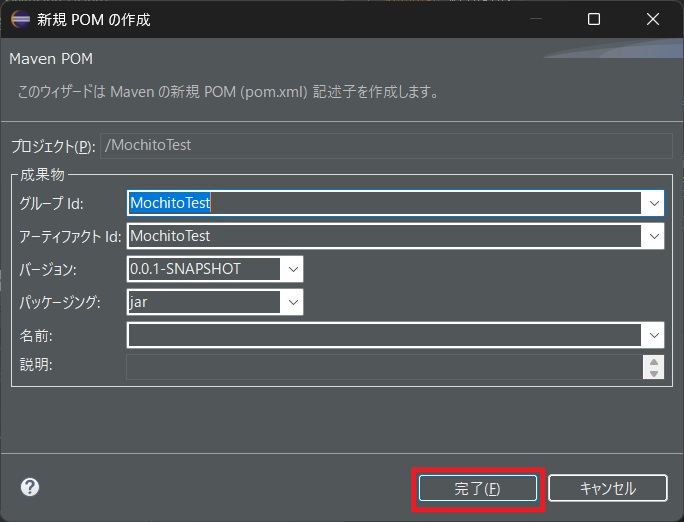
すると、JavaプロジェクトがMavenプロジェクトに変換され、Mavenを使用したライブラリ取り込みが可能になります。
以下のようにpom.xmlが出力されていれば成功です。
【Mockitoの導入】
pom.xmlを修正し、Mockitoを取り込むdependencyタグの設定を記述します。
・pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>MochitoTest</groupId>
<artifactId>MochitoTest</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-core</artifactId>
<version>4.0.0</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<release>11</release>
</configuration>
</plugin>
</plugins>
</build>
</project>
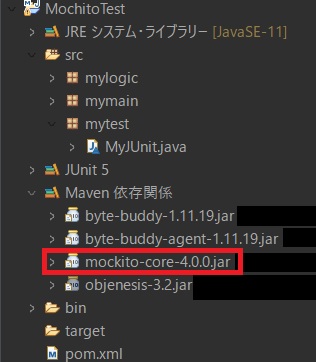
pom.xmlを保存すると、Mavenにより、Mockitoが自動で取り込まれます。
以下のように依存関係にMockitoが表示されれば成功です。
【Mockitoを用いたテストの実施】
いよいよ、テストクラスであるMyJUnitクラスでMockitoを使用します。
モックオブジェクトに置き換えたいオブジェクトは、MyLogicSubクラスのオブジェクトです。
それを示すために、MyLogicSubクラスを定義する箇所で@Mockアノテーションを定義します。
また、それを使用するMyLogicクラスを定義する箇所では@InjectMocksアノテーションを定義します。
テストメソッドを実行する前に実行されるメソッドとして、initMocksメソッドを定義します。
ここでは、MockitoAnnotationsクラスのopenMocksメソッドを、テストクラス(this)を引数にして実行します。
これにより、前述のアノテーションが使用可能になります。
そして、モックオブジェクトの処理内容は、テストメソッド中に記述します。
今回は以下のような記述を行っています。
String productCode = "0020";
Mockito.doReturn(20).when(myLogicSub).searchStockAmount(productCode);
これは、「myLogicSubクラスのsearchStockAmountメソッドが呼ばれた時、引数に"0020"(変数「productCode」の値)が与えられていれば、戻り値として20を返す」という意味です。
つまり、myLogicSubクラスを以下のような処理内容に置き換えたのと同じ意味です。
public class MyLogicSub {
/* 商品コードから在庫量を取得 */
public int searchStockAmount(String productCode) {
int stockAmount;
if (productCode = "0020") {
stockAmount = 20;
}
return stockAmount;
}
}
このmyLogicSubクラスのモックオブジェクトを利用することで、処理結果が意図した一定の値になるようになり、テストが成功するようになります。
ここまで書いた内容をソースコードとしてまとめると以下の通りです。
・MyJUnit.java
package mytest;
import static org.junit.jupiter.api.Assertions.*;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.mockito.InjectMocks;
import org.mockito.Mock;
import org.mockito.Mockito;
import org.mockito.MockitoAnnotations;
import mylogic.MyLogic;
import mylogic.sub.MyLogicSub;
class MyJUnit {
@InjectMocks
private MyLogic myLogic;
@Mock
private MyLogicSub myLogicSub;
@BeforeEach
public void initMocks() {
MockitoAnnotations.openMocks(this);
}
@Test
void test() {
String productCode = "0020";
Mockito.doReturn(20).when(myLogicSub).searchStockAmount(productCode);
assertEquals(20, myLogic.getStockAmount(productCode, myLogicSub));
}
}
テストが必ず成功するようになれば、Mockitoの利用に成功しています。
このように、Mockitoを用いれば、テスト対象のクラスから呼び出されるクラスの処理を意図通りの仮の値とすることができるようになります。
テスト対象のクラスから呼び出されるクラスの処理が意図しない値を返すことによるテスト失敗がなくなるため、テスト対象のクラスの処理内容のテストに集中することができるようになります。


 続いて、私の方で手作業で検算を行い、出力された結果が正しいことを確認しました。
続いて、私の方で手作業で検算を行い、出力された結果が正しいことを確認しました。















