表題の通りですが、実装では極力要件通りに条件指定をするべきです。
従属的に求まる条件で代用できるとしても、その条件は原則として指定するべきではありません。
具体的に何が言いたいのか、なぜそう言えるのか、ということについて、以下で具体例を挙げて説明していきます。
----
例えば、
「商品区分が"1"の場合だけ、特別な処理をしたい」
という要件があったとします。
また、実装上は、
「商品区分が"1"の場合は、商品コードの2桁目が"1"になる」
という従属条件も存在するとします。
この場合、実装方針としては、以下の2つが考えられます。
方針1:商品区分が"1"であるかどうかを見る
方針2:商品コードの2桁目が"1"であるかどうかを見る
そして、この場合は、できる限り方針1で実装するべきです。
そう言える理由は以下の2つです。
理由1:可読性を損なわないようにするため
理由2:将来の変更に弱くなりにくくなるため(保守性の確保)
理由1については、新たな実装者を向かい入れることを考えるとわかりやすいと思います。
「商品区分が"1"の場合は、商品コードの2桁目が"1"になる」という従属条件を知っていれば何がしたいのかコードを見て推測できますが、そうでないとコードからは何がしたいのか推測できなくなるので、可読性が損なわれやすくなります。
理由2については、従属条件には例外がつきものということを意識する必要があります。
例えば、ある時点では「商品区分が"1"の場合は、商品コードの2桁目が"1"になる」が成り立っていたとしても、商品コードの採番が進むにつれて「取り扱う商品が多くなってきたので、商品コードの2桁目が"A"の場合も商品区分"1"として取り扱う」という例外が発生する可能性があります。
この際に実装の改修が発生してしまいますし、改修が漏れた場合は「商品コードの2桁目が"A"の場合に、特別な処理が行われなくなる」という障害になってしまいます。
----
従属的に求まる条件で代用する場合は、可読性・保守性以外の観点で止むに止まれぬ事情がある場合に限るべきです。
例えば、「納期に間に合わせるため」というのは、止むに止まれぬ事情の一つとして考えられます。
具体的には「要件通りの条件は連携されていない、連携してもらう時間もない」というような状況です。
しかし、止むに止まれず従属的に求まる条件で代用する場合は、可読性や保守性をできる限り損なわないようにする工夫をするべきです。
例えば、本来は何がしたいのか、ということをコメントに残すというのは、可読性を損なわないようにする上で重要です。
「要件通りの条件指定に直す」というタスクを作って管理する、というのも保守性を確保する上では良い工夫です。
SpringFramework:cronによるスケジューリング
cronと言えば、Linuxに用意されているスケジュール用のプロセスを思い浮かべる方が多いと思います。
(Linuxのcronについては、Wikipedia(https://en.wikipedia.org/wiki/Cron)等を参照してください)
しかし、cronはSpring Frameworkにも用意されています。
プロセス常駐のアプリケーション中で、アノテーションを用いて、cronの記法でスケジューリングをすることができます。
Springのcronの記法は、Linuxのcronの記法と基本的には同じですが、Springのcronでは秒が指定できる点が異なります。
Linuxでは「分 時 日 月 曜日」の順番に指定しますが、Springでは「秒 分 時 日 月 曜日」の順番に指定します。
秒まで指定できるため、秒単位のスケジューリングをしたい場合にLinuxのように処理中でsleepを噛ませる必要はありません。
Springのcronについての詳細は、公式ドキュメント(https://spring.io/blog/2020/11/10/new-in-spring-5-3-improved-cron-expressions)を参照してください。
以下、サンプルコードです。
今回は、EclipseでSpring Boot STSを使用しています。
また、ビルドツールはGradleを使用しています。
【前準備】
Eclipseで下記操作を行い、プロジェクトを作成する。
・ファイル→新規→その他→Spring Starter Project
・名前に「SpringCronTest」、グループに「com.example」、パッケージに「com.example.demo」を指定し、次へ
・何も選択せずに完了
【サンプルコード】
・build.gradle
plugins {
id 'org.springframework.boot' version '2.6.1'
id 'io.spring.dependency-management' version '1.0.11.RELEASE'
id 'java'
}
group = 'com.example'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '1.8'
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter'
compileOnly group: 'org.projectlombok', name: 'lombok', version: '1.18.10'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
test {
useJUnitPlatform()
}
・SpringCronTest.java
package com.example.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableScheduling;
@SpringBootApplication
@EnableScheduling
public class SpringCronTest {
public static void main(String[] args) {
SpringApplication.run(SpringCronTest.class, args);
}
}
・Run.java
package com.example.demo;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
@Component
public class Run {
private SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
@Scheduled(cron="*/5 * * * * *")
public void execute() {
System.out.println("定期実行:" + sdf.format(new Date()));
}
}
【実行方法】
SpringCronTest.javaを右クリックし、実行→Spring Boot アプリケーションを選択
【実行結果】
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.6.1)
2021-12-04 23:25:52.531 INFO 9696 --- [ main] com.example.demo.SpringCronTest : Starting SpringCronTest using Java 1.8.0_162 on hama001 with PID 9696 (C:\pleiades\workspace\SpringCronTest\bin\main started by hamattyattahito001@h in C:\pleiades\workspace\SpringCronTest)
2021-12-04 23:25:52.547 INFO 9696 --- [ main] com.example.demo.SpringCronTest : No active profile set, falling back to default profiles: default
2021-12-04 23:25:54.509 INFO 9696 --- [ main] com.example.demo.SpringCronTest : Started SpringCronTest in 3.347 seconds (JVM running for 5.779)
定期実行:23:25:55
定期実行:23:26:00
定期実行:23:26:05
定期実行:23:26:10
定期実行:23:26:15
定期実行:23:26:20
2021-12-04 23:26:22.041 INFO 9696 --- [on(2)-127.0.0.1] inMXBeanRegistrar$SpringApplicationAdmin : Application shutdown requested.
ひと昔前のソース管理の問題点
GitやGit系ホスティングサービスが広まった現在のシステムでは、以下のようなソース管理が一般的です。
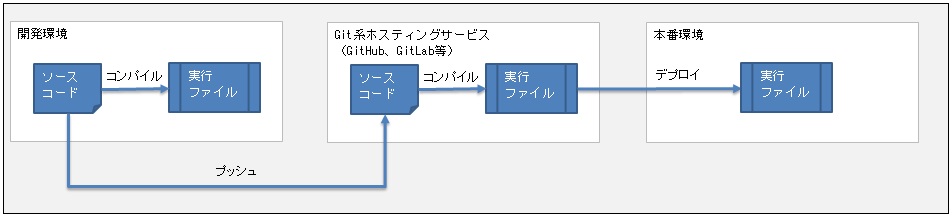
しかし、それが広まる前のひと昔前のレガシーシステムでは、以下のようなソース管理が一般的でした。
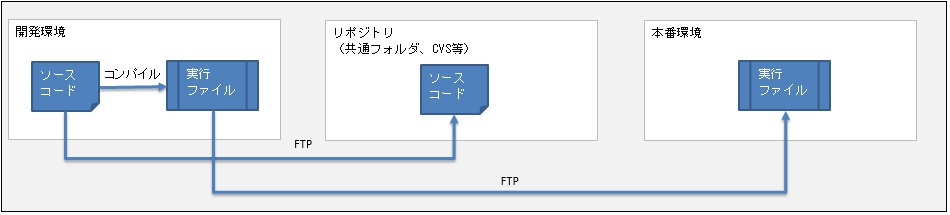
この記事では、ひと昔前のソース管理の問題点を挙げていきます。
----
ひと昔前のソース管理の問題点は、以下の二つです。
①本番環境に配置される実行ファイルがどのように作られたのか不明である
②最新のソースコードが適切に管理されない可能性がある
以下では、それぞれの問題点について説明します。
①本番環境に配置される実行ファイルがどのように作られたのか不明である
現在のソース管理では、Git系ホスティングサービスの中でコンパイル(ビルド)が行われます。
このコンパイルの作業は、Git系ホスティングサービスの管理者が実施するため、開発者任せになることがなく、どのソースファイルがコンパイルされたのかも明確です。
しかし、ひと昔前のソース管理では、開発者がコンパイルした実行ファイルをそのまま本番環境に持ち込みます。
そのため、コンパイル作業が開発者任せになりますし、どのソースファイルがコンパイルされたのかも不明になります。
(開発者の環境を見に行って推測したり、開発者の申告を信じたりするしかありません)
ひと昔前のソース管理では、この問題により、意図しないソースファイルがコンパイル時に含まれてしまうことによるデグレードが起こりやすくなります。
②最新のソースコードが適切に管理されない可能性がある
現在のソース管理では、本番環境向けにコンパイルを行ったソースファイルをそのまま世代管理します。
そのため、本番環境向けのコンパイルに使用したソースファイルの紛失は起こりにくいです。
しかし、ひと昔前のソース管理では、リポジトリへのソースファイル格納と本番環境への実行ファイル配置は別作業になり、リポジトリへのソースファイル格納を忘れても本番運用には影響がない、という状態が起こり得ます。
このことにより、ソースファイルの世代管理の作業が漏れやすくなり、ソースファイル紛失の原因になります。
(例えば、リポジトリへのソースファイル格納を忘れ、かつ開発環境のリプレースが発生した場合、リプレース前の開発環境にのみ存在していたソースファイルは失われてしまいます)
Excel:文字コードのBOMについて
「UTF-8」や「UTF-16」等の一部の文字コードには、「BOM」と呼ばれるフラグのようなものを付ける場合があります。
BOMはファイルの先頭につけられるバイナリのデータであり、UTF-8の場合は16進数で「EF BB BF」、UTF-16の場合は16進数で「FE FF」となります。
(詳しくは、英語版のWikipedia(https://en.wikipedia.org/wiki/Byte_order_mark)に記載があります)
BOMは、そのファイルが何の文字コードを使用しているか判定するために用いられるものです。
BOMは現在は使用されることが少なく、使用すると逆にトラブルの元になることもあります。
しかし、現在でもBOMを使用するソフトウェアは存在し、その代表例はExcelです。
Excelでは標準の文字コードがSJISですが、BOM付きのファイルを読み込んだ場合はBOMが示す文字コードが使用されます。
以下では、読み込みと書き込みの例を示します。
【読み込み】
以下はBOM無しのUTF-8のCSVファイルです。
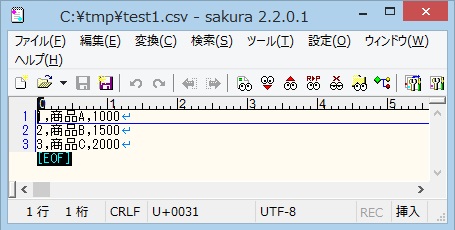
バイナリエディタでファイルを開くと以下の通りです。
ファイルの先頭に「EF BB BF」がありません。

これをExcelで開くと、SJISと判定され、文字化けします。

今度は、同じデータで、BOMを付与したCSVファイルを用意します。
バイナリエディタでファイルを開くと以下の通りです。
ファイルの先頭に「EF BB BF」があります。これがBOMです。
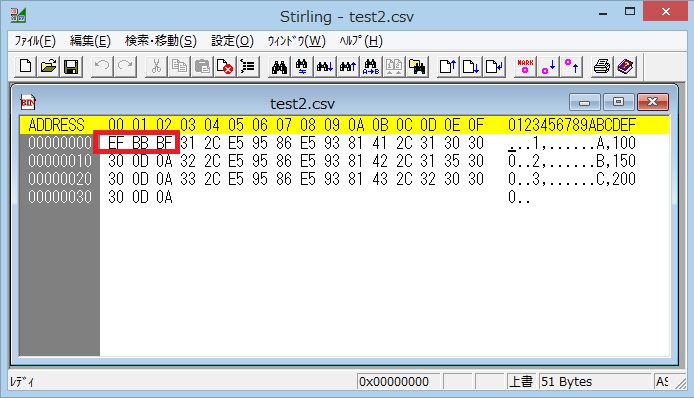
これをExcelで開くとUTF-8と判定され、文字化けしません。

【書き込み】
Excelで開いたCSVファイルを、「Unicodeテキスト(*.txt)」形式で保存します。
すると、BOM付きのUTF-16形式でデータが保存されます。

これをExcelで開くと、UTF-16形式のBOMである「FE FF」が確認できます。

設計書のメンテナンスのあるべき姿
設計書は、システム概要を指し示すために必要なドキュメントです。
設計書があれば、実装を知らない立場の人(例えば要件定義担当や上位の設計者)との意思疎通がスムーズになりますし、開発者を新たに向かい入れる時にも実装の内容をスムーズに理解してもらえるようになります。
実装を確認しなければならない時もありますが、それは詳細を確認する必要がある場合や、実際にソースコードを改修する場合に限られます。
----
ここまでが本来のあるべき姿なのですが、実際の現場では設計書をあてにせずに実装を見る文化になっている現場もあります。
そのような文化になってしまう原因は、設計書の信頼性が低いことにあります。
「設計書の信頼性が低い」というのを具体的に書くと、「設計書が実装と乖離しており、正しいのは実装の方」ということです。
そのような設計書には、情報の誤りや不足が見られます。
「情報の誤りや不足」というのは、具体的な例えを出すと以下のようなものです。
・2021年時点で消費税は10%に上がっているのにも関わらず、「消費税は8%である」という現時点では誤りとなる記述が残っている。(情報の誤り)
・2021年時点では店頭で購入できるカロリーメイトはブロックタイプ・ゼリータイプ・リキッドタイプの3種類あるのにも関わらず、「店頭で購入できるカロリーメイトはブロックタイプとゼリータイプの2種類である」という現時点では不足となる記述が残っている。(情報の不足)
設計書に情報の誤りや不足が見られても、実装が正しければ、今この瞬間ではユーザーに迷惑がかかることはありません。
しかし、設計書に情報の誤りや不足が見られる場合は、その設計書を元に意思疎通や実装理解を行うと、情報の伝達や理解が正しく行われず、それが将来の障害の原因になり、ユーザーに迷惑をかけることになります。
そのような障害の可能性をなくすため、設計書はあてにせずに実装を見る、という文化が生まれます。
設計書はあてにせずに実装を見る、という文化は、近い将来は上手く回りますが、人員が変更になるタイミングで問題が顕在化します。
開発者とその周りの人が変わらないのであれば、システム概要が暗黙知的に共有されているため、情報の伝達や理解を正しく行うことができます。
しかし、設計書がなければシステム概要が形式知にならないため、次の開発者がシステム概要を理解することが困難になってしまいます。実装を全て見なければシステム概要を理解できない状態となり、引継ぎに時間を要するようになってしまいます。
その周りの人も、人員が入れ替わった時に、実装レベルで細かく見る必要が出てきてしまいます。
将来の人員変更も考えると、設計書はあてにせずに実装を見る、という文化は、大きなコストとリスクを抱えることになってしまいます。
システムを運用・保守する上では、設計書のメンテナンスは欠かせないものであり、設計書がメンテナンスされ続けて実際に読まれることがあるべき姿です。
----
設計書がメンテナンスされなくなってしまう理由は、設計書のメンテナンスに工数を要するためです。
工数に余裕がない案件では、設計書のメンテナンスはどうしても後回しになってしまいます。
しかし、設計書のメンテナンスに工数を要してしまうのは、設計書が正しく書かれていないから、というのもあります。
もし、設計書がシステム概要を示すものではなく、実装とほぼ1対1なのであれば、設計書の記述量は実装とほぼ同程度となってしまい、記述量が多い分、設計書のメンテナンスの工数も増えてしまいます。
設計書がシステム概要を示すものなのであれば、設計書のメンテナンスの工数は少なくとも実装ほど大きくはならないはずです。
そして、設計書が正しく書かれているのであれば、実装の助けにもなるはずです。
実装をする際には思考の整理が必要になりますし、複数人で開発しているのであれば意思疎通も必要になります。
もし、設計書が正しくシステム概要を示すものであり、実際に実装の助けになるものなのであれば、設計書をメンテナンスした方が実装もスムーズに進むはずです。
「将来のことを考えて仕方なくメンテナンスする」という感覚ではなく、「メンテナンスされないと今この瞬間に困るからメンテナンスする」という感覚になるはずです。
まとめると、システム概要が示され思考の整理の役に立つ設計書を書くことが、設計書が継続的にメンテナンスされるというあるべき姿に近づくための方法である、ということになります。
高度な技術が最適解とは限らない
AIや難しいアルゴリズムに憧れる人は少なくないと思いますが、そのような高度は技術が常に最適解であるとは限りません。
高度ではない技術には、以下のようなメリットがあります。
・人間が結果を予想しやすい
・保守が容易である
一言で言うと、「扱いやすい」ということがメリットになります。
高度ではない技術は、人海戦術になりがちで導入コストがかかり、システム構築時のヒューマンエラーも起こりがちですが、システムを保守・運用する上では、そのようなデメリットよりも「扱いやすい」というメリットが上回る場合が少なくありません。
この記事では、高度ではない技術の方が優れていたという例を2つ挙げます。
1.ソースコードの変数名の翻訳
ある現場では、ソースコードの変数名を日本語から英語へ翻訳して書き変える、という案件が走っていました。
この案件では、当初は「形態素解析」と呼ばれる技術を使うことが検討されました。
この技術は、文章の文法を読み解き、文章中に含まれる単語を切り分ける、という高度な技術です。
しかし、形態素解析を用いた解釈とその解釈結果に基づく翻訳を試みた所、翻訳結果を予想しにくいという問題が発見されました。
ソースコードの変数名を翻訳する場合、翻訳結果が予想できないとバグに繋がるため、この問題は致命的でした。
(例えば、翻訳した結果変数名が被ったり、同じ変数が異なる翻訳結果になったりした場合、そのソースコードから作られたロードモジュールの挙動が変わってしまう)
検討した結果、形態素解析は用いず、csvの定義ファイルを用いた単純なパターンマッチングにより翻訳を行うことになりました。
csvの定義ファイルは約8,000レコードであり、その定義ファイルを作成するのに人手が必要になりましたが、結果として翻訳したプログラムは安定稼働しており、案件は成功を収めました。
2.RPGの複雑なバリデーションチェック
あるRPG(ロールプレイングゲーム)を攻略する上では、そのRPGのシミュレーターを作成し、シミュレーターにより最適解を探し出す、という手段が有効です。
このシミュレーターでは、実際のRPGと同じ状況を再現するために、入力のバリデーションチェックの実装が必要になります。
今回問題になるバリデーションチェックは、キャラクターが覚える技の組み合わせに関するバリデーションチェックです。
攻略対象であったRPGでは、キャラクター毎に覚える技が決められており、またキャラクターの育成方法によっても覚えられる技が変わってきます。
育成方法に関する条件は大きく分けて5つあり、その5つの条件について、キャラクター毎に細かい分岐条件を考える必要がある、というものでした。
シミュレーターは日本製と海外製の2つがありますが、それぞれで実装方針が以下のように異なっていました。
日本製:人手をかけて調査し、調査結果を約15,000レコードのcsvファイルにまとめる。
海外製:「NP完全問題」を解く、というアプローチで高度なアルゴリズムを実装。
結果として、日本製のシミュレーターにも、海外製のシミュレーターにも、実装ミスはありました。
しかし、日本製のシミュレーターは、csvファイルのレコードを書き変えるだけで改修作業が完了するので、実装ミスに対して容易に対応することができました。
また、csvファイルは人間が読んでも意味がわかるものなので、プログラムによるバリデーションチェックで使うだけでなく目視のチェックにも使える、という副次的なメリットもありました。
それに対して、海外製のシミュレーターは、複雑なアルゴリズムを読み解かないと実装ミスへの対応ができません。
結果として、誰も修正することができず、実装ミスが放置され続けています。
文字コードの入門
この記事では、文字コードに関する初歩的な内容について簡単に書きます。
1.文字コードという概念とコード体系
コンピューターで取り扱う文字には、それぞれコードが割り振られています。
コードは1~4バイトの情報として取り扱われ、1バイトの文字は1バイト文字、2~4バイトの文字はマルチバイト文字と呼ばれます。
原則として、半角英数字記号は1バイト文字として扱われ、それ以外の文字はマルチバイト文字として扱われます。
(ここでは詳しく触れませんが、半角カナや人間には読めない制御文字は、1バイト文字のこともあればマルチバイト文字のこともあります)
これらの情報は、16進数で表現されることが多いです。また、プログラム上では、10進数で表現されることも多いです。
どの文字にどのコードが割り振られるのかは、コード体系によって決まります。
1バイト文字に関しては、今日のPCではASCIIというコード体系が使われます。
ASCIIにて、どの文字にどのコードが割り振られているのかは、以下の表から確認することができます。
(例えば、「A」には「0x41」(10進数で「65」)が、「a」には「0x61」(10進数で「97」)が割り振られています)
https://ja.wikipedia.org/wiki/ASCII
また、ホストコンピューターでは、1バイト文字にEBCDICという別のコード体系が使われます。
EBCDICの表は以下の通りであり、ASCIIとは異なる割り振られ方をしていることがわかります。
(例えば、「A」には「0xC1」(10進数で「193」)が割り振られています)
https://ja.wikipedia.org/wiki/EBCDIC
マルチバイト文字については、今日ではUTF-8やShiftJISといったコード体系が使われることが多いです。
(マルチバイト文字に関しては、この記事では詳細を割愛します)
2.ソースコード上で文字コードを取り扱う例
ソースコード上でも、文字コードを取り扱うことができます。
と言うより、文字は内部的には文字コードであり、「A」や「a」といった表示は人間が読みやすいように表現しているものです。
以下は、「A」や「a」といった文字が内部的にどのような文字コードを持っているのかを表示するJavaのプログラムです。
ASCIIコード表通りの文字コードが割り振られていることを確認できます。
■ソースコード
・CharCode1.java
public class CharCode1 {
public static void main(String args) {
// 「A」を文字コードとして表現
String char_A = "A"; // 文字列"A"を定義
short code_A = (short)char_A.charAt(0); // 文字列"A"を文字コードに変換
System.out.println("「" + char_A + "」の文字コード:" + code_A); // 表示
// 「a」を文字コードとして表現
String char_a = "a"; // 文字列"a"を定義
short code_a = (short)char_a.charAt(0); // 文字列"a"を文字コードに変換
System.out.println("「" + char_a + "」の文字コード:" + code_a); // 表示
}
}
■実行結果
「A」の文字コード:65
「a」の文字コード:97
また、文字の比較も、文字コードにより行うことができます。
以下は、「ABC」という文字列を前から1文字ずつ読み込み、「B」の文字を読みこんだ時だけ表示を行うJavaのプログラムです。
■ソースコード
・CharCode2.java
public class CharCode2 {
public static void main(String args) {
// 文字列「ABC」を1文字ずつ読込
String str = "ABC"; // 文字列"ABC"を定義
for (int i = 0; i < str.length() ; i++) { // 1文字ずつループ
short code = (short)str.charAt(i); // 読み込んだ文字の文字コード取得
if (code == 66) { // 文字コードが66("B")の場合
// if (str.substring(i, i+1).equals("B")) { // このように書いても同じ
System.out.println((i + 1) + "番目の文字:" +
str.charAt(i) + " 文字コード:" + code);
}
}
}
}
■実行結果
2番目の文字:B 文字コード:66
3.文字コードを意識する理由
ここで、「なぜプログラミングで文字コードを意識する必要があるのか」と疑問を持った方もいらっしゃるかもしれません。
確かに、人間には読みにくい文字コードを使ったプログラミングをするよりも、文字を直接使ったプログラミングの方が望ましいように思えます。
例えば、この記事で2つ目に取り上げたソースコード(CharCode2.java)では、文字コードを使用しなくても文字コードを使った時のような制御を実現でき、それならば文字コードを使った制御をしない方が望ましいように思えます。
それでも文字コードを意識する一番の理由は、バイナリの制御文字を取り扱うために必要だからです。
文字には、人間が読める文字の他に、コンピューターに命令を送るための制御文字が存在します。
多くの人にとって一番馴染みがある制御文字の一つが「改行文字」です。
コンピューターが改行文字を読みこむと、文章の改行が行われます。
(この記事が正しく改行されて読みやすくなっているのも、この「改行文字」のおかげです)
改行文字はOSによって割り振られている文字コードが異なりますが、Unix/Linuxの場合は「10」が割り振られています。
この文字は、プログラム上で"A"や"a"といった形で記述することができず、プログラミング言語やライブラリでサポートされない場合は、文字コードを参照しないと改行文字であるか否かを判定できません。
例えば、Javaで絵文字を含む文字列を1文字ずつ切り取る場合に、文字コードの参照が必要になります。
解説やコード例は以下の記事に書いています。
java:Unicodeの絵文字をjavaで取り扱う
文字コードについてプログラミングの入門書に書かれていることは少ないですが、実務では度々目にします。
実務でプログラミングをするのであれば、文字コードについても早めに勉強しておくことをお勧めします。