通常のシステムでは、データベースやファイル等にデータを蓄積します。
そして、システムの改修の際に、そのデータのフォーマットを変更することがあります。
データのフォーマットの変更には、「これまでに蓄積されたデータをどのように扱うのか」という問題が付きまといます。
開発者は、データを移行するのかしないのか、移行するのであればどのように移行するのか、ということを判断する必要があります。
ここでは、データ移行について、具体的な例を用いて見て行こうと思います。
【例】
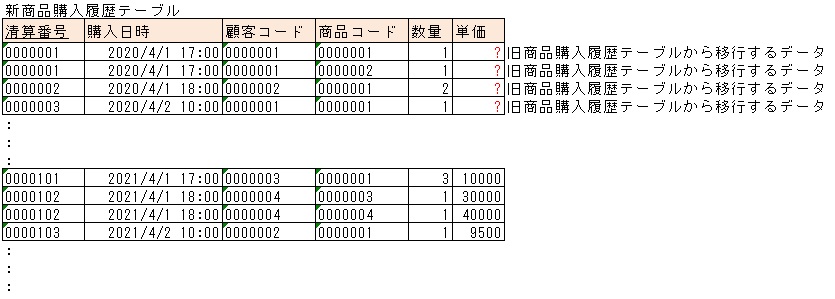
商品購入履歴テーブルにて、清算番号をキーとし、いつ誰が何をどれだけ購入したのかを管理しているとします。
システム稼働開始時は、商品コードから単価は一意に求まるとします。
また、当該テーブルを見て、各々の顧客が過去に商品を購入したことがあるかどうかを見る必要があるとします。
ここで、各々の清算において値引きを可能にするシステム改修を行うとします。
また、売り上げを正しく求めるため、清算毎の単価を新たに管理する必要が出てきたとします。
この場合、商品購入履歴テーブルのフォーマットを以下のように変更する必要が出てきます。
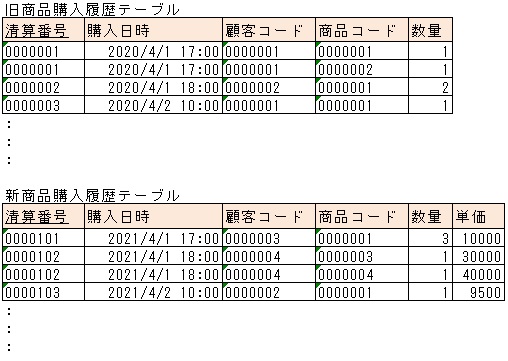
ここで、過去に蓄積されたデータの扱いについて、以下のような方針を考える必要が出てきます。
【対応方針】
1.データ移行せず、旧商品購入履歴テーブルをそのまま残す
データ移行が困難であり、プログラムの改修箇所が少ないのであれば、データ移行しないという選択肢があります。
データ移行が困難な状況としては、データ量が多く時間がかかる、システムを停止できる時間が少ない、といった要因があります。
この方針の場合、過去の購入履歴を参照するプログラムに対して改修が必要になります。
新商品購入履歴テーブルと旧商品購入履歴テーブルの両方を見る、という改修を行う必要があります。
例えば、顧客コード"0000001"の顧客が過去に商品を購入したかどうかを見たい場合、新商品購入履歴テーブルになければ旧商品購入履歴テーブルを見る、とする必要があります。
この方針のデメリットとしては、プログラムロジックが複雑になり、保守性が低下することが挙げられます。
もし、自動化されていない運用作業で商品購入履歴テーブルを見る必要がある場合、その作業が煩雑になることにも注意する必要があります。運用ミスの原因にもなり得ます。
2.データ移行する
データ移行する場合、旧商品購入履歴テーブルのデータを、新商品購入履歴テーブルに移し替える必要があります。
システムを一時的に停止し、移行用のプログラムを実行させ、旧商品購入履歴テーブルのデータを新商品購入履歴テーブルのフォーマットに合わせた形で移行します。
(失敗に備えてバックアップを取得することも重要です)
データ移行する際には、フォーマットをどのように合わせるのかを考える必要があります。
今回の例で言うと、移行したデータの単価に何をセットするのか、ということを考える必要があります。
移行日以前の単価を見る必要が無いのであれば、nullで問題ありません。
見る可能性があるのであれば、現在の単価(過去に単価が変動しているのであれば当時の単価)をセットする必要があります。